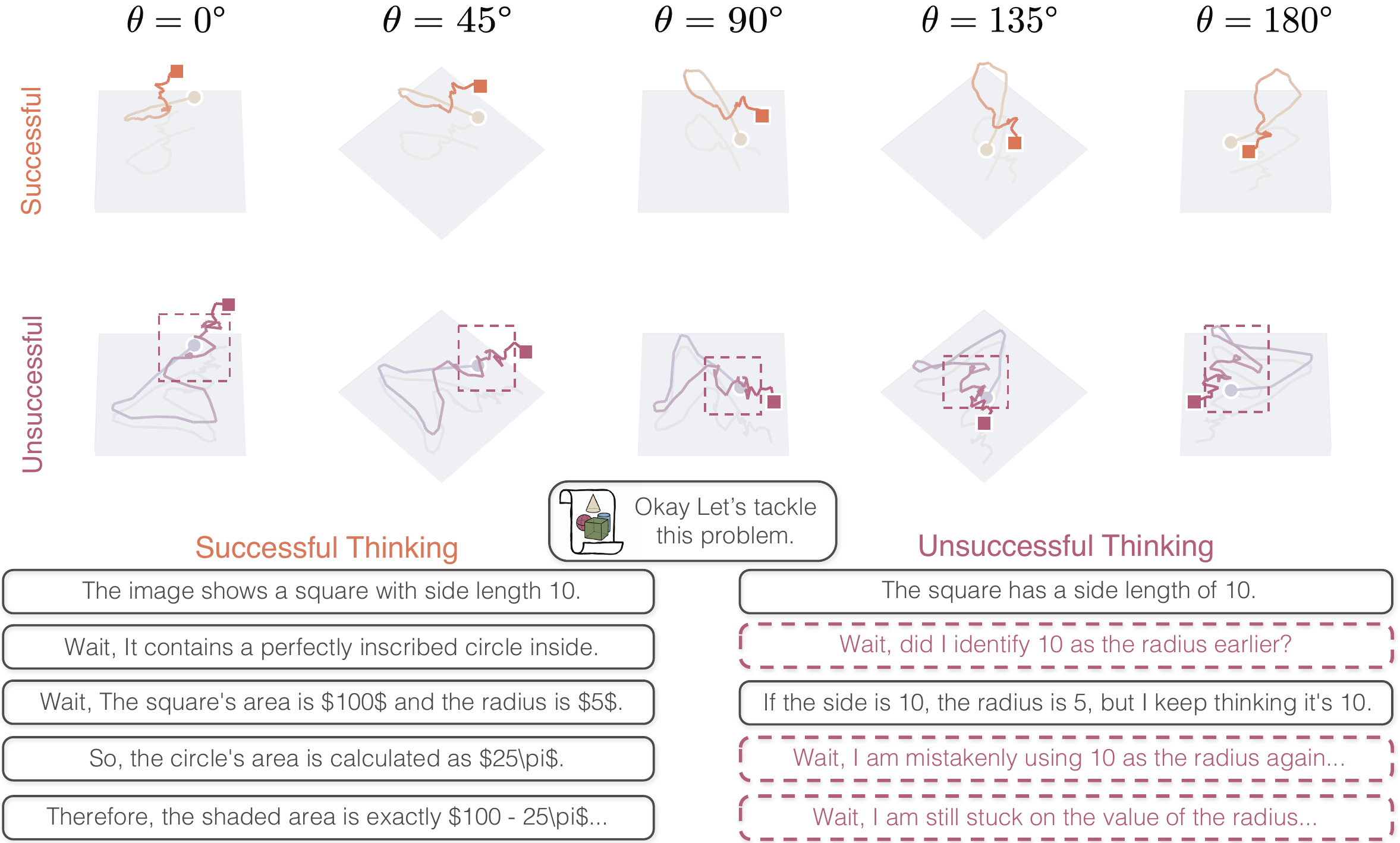
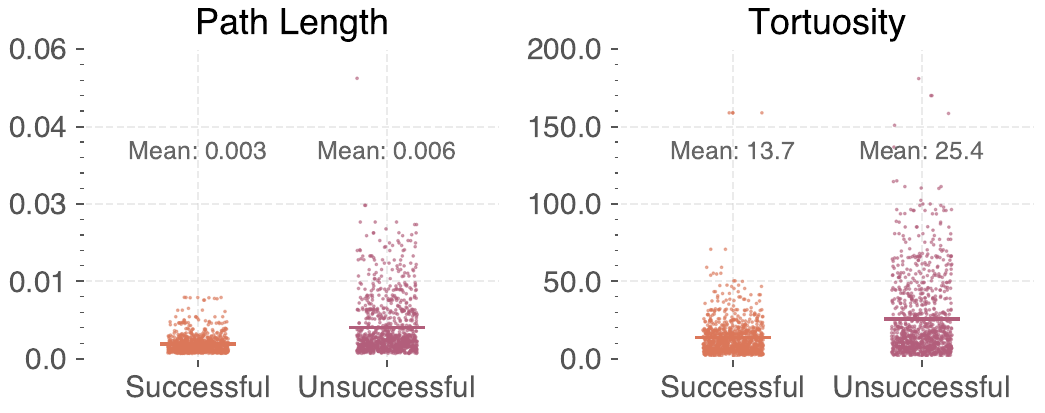
Motivation
The faithfulness–efficiency gap
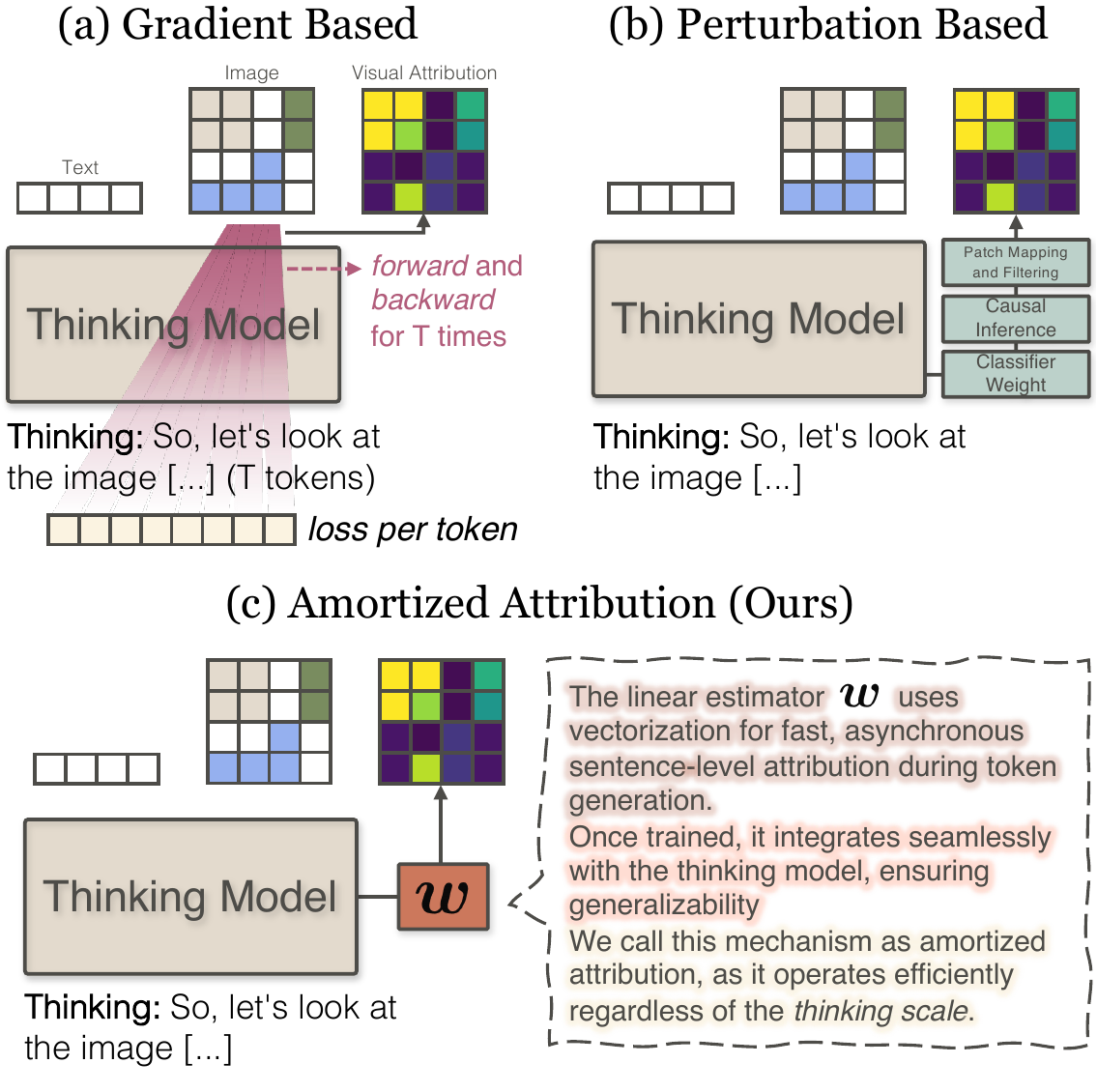
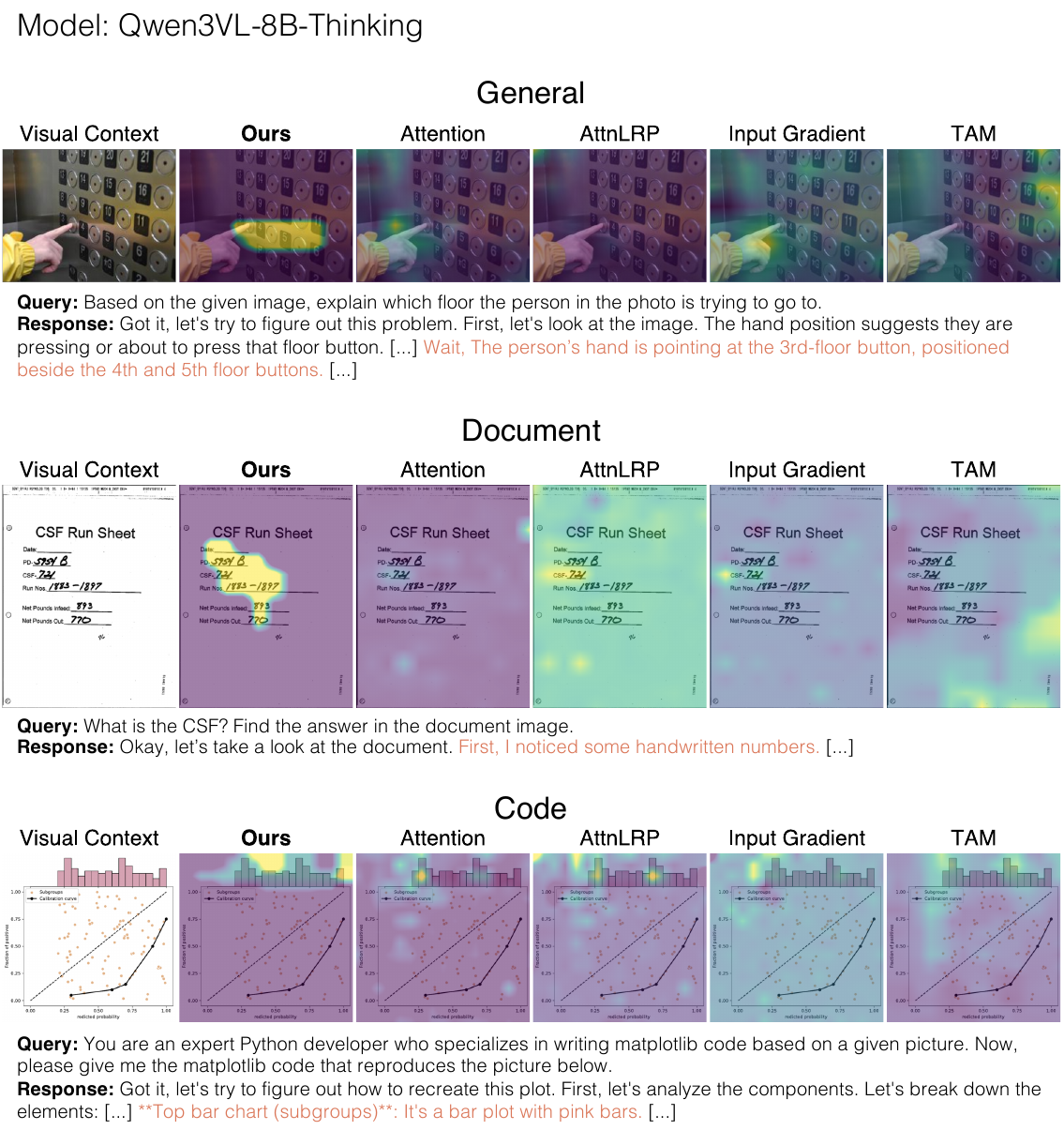
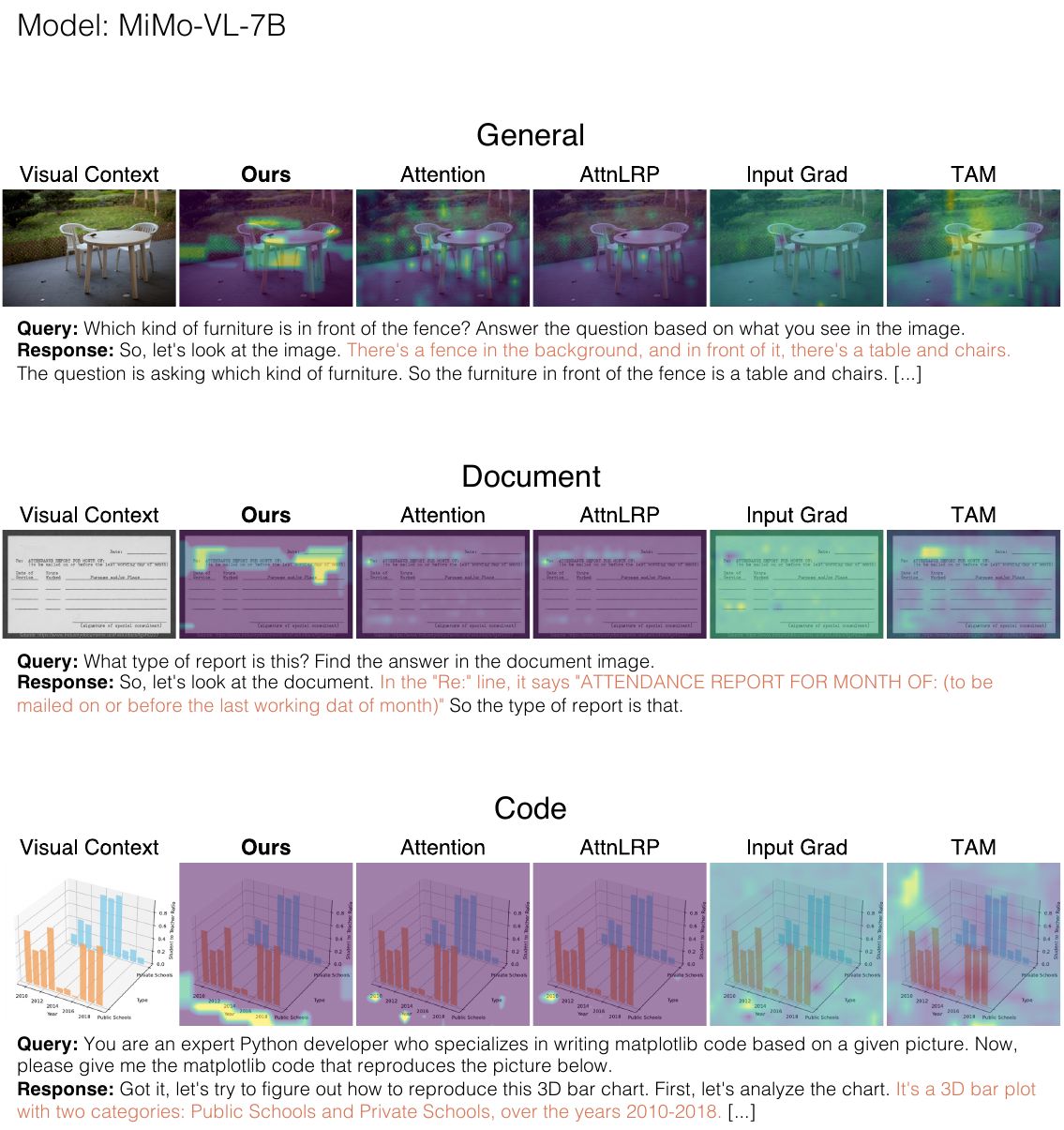
Multimodal reasoning models generate extended thinking traces that should be grounded in visual evidence. Verifying that grounding is hard: faithful causal methods require costly perturbations that scale with trace length, while raw attention weights are instant but causally unreliable.
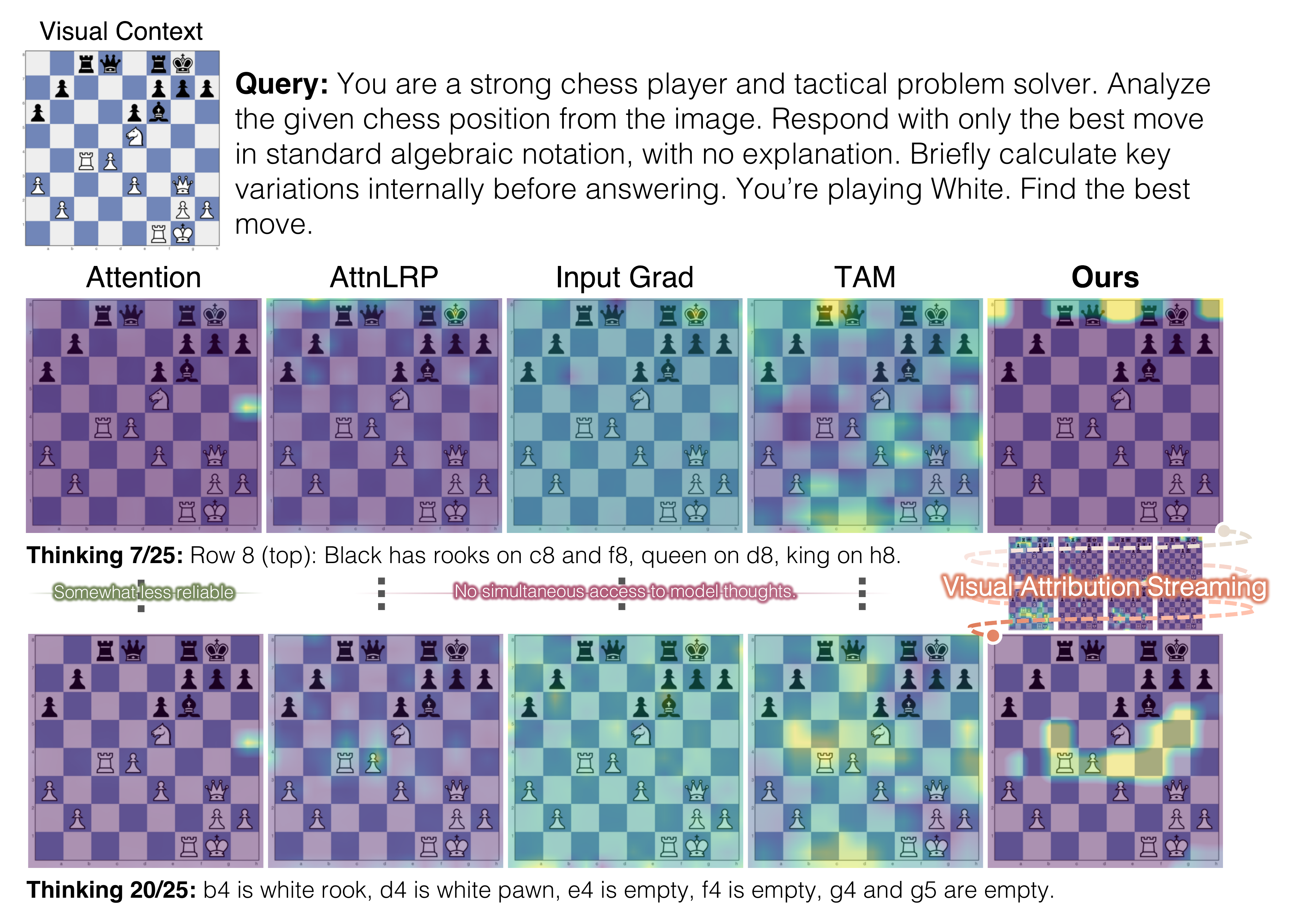
As reasoning traces extend to thousands of tokens, per-token latency for perturbation-based methods grows to the point where real-time analysis becomes infeasible for interactive debugging. A model may cite "the angle at vertex B" while attending to an irrelevant region, and existing methods either can't tell you, or tell you too slowly.
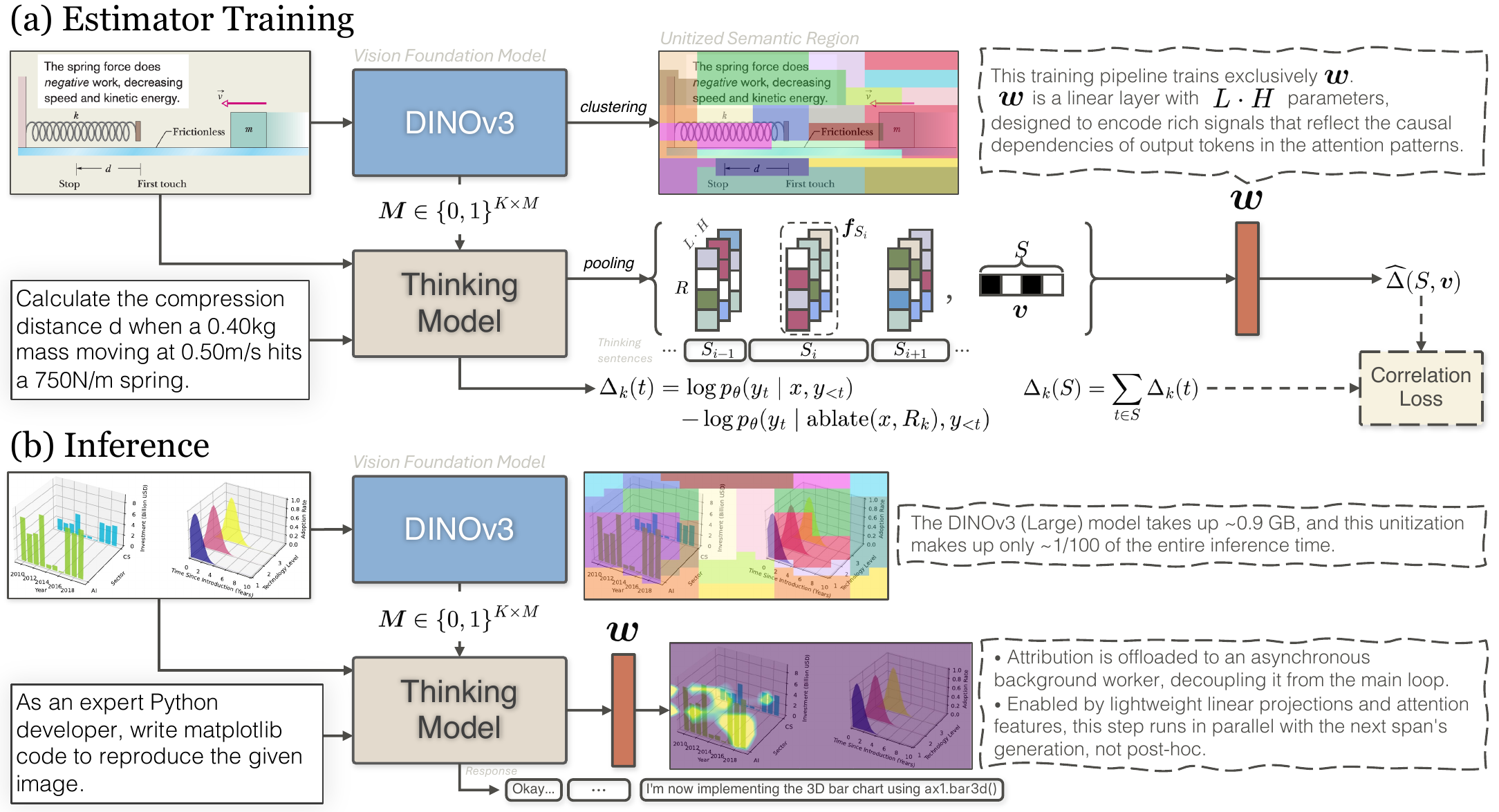
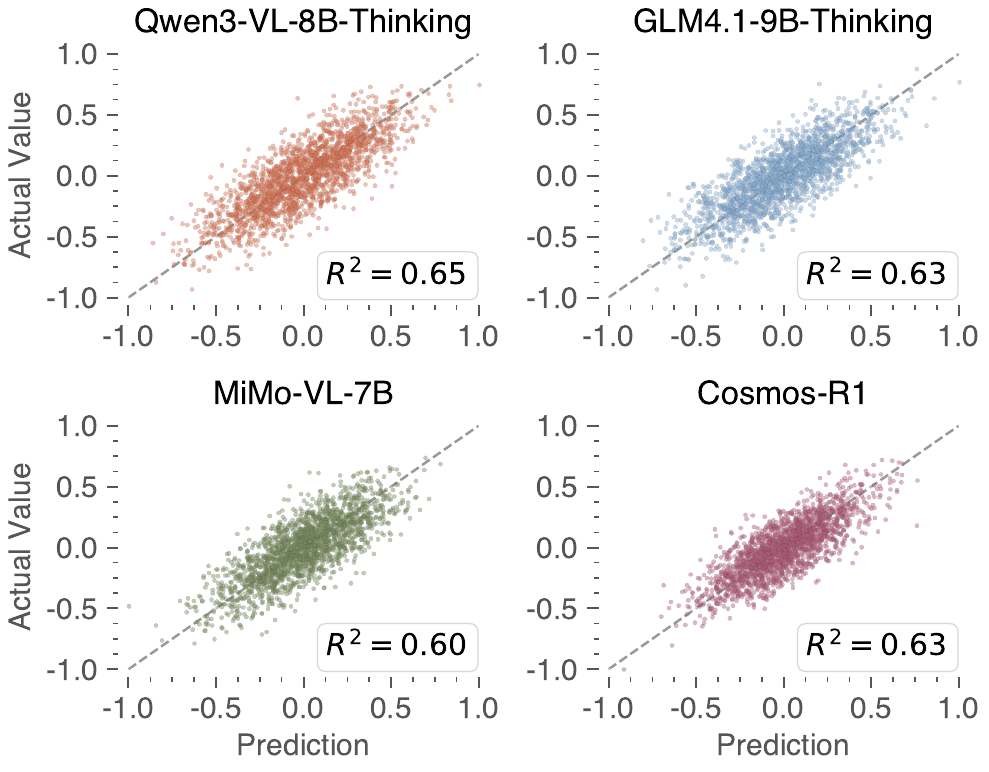
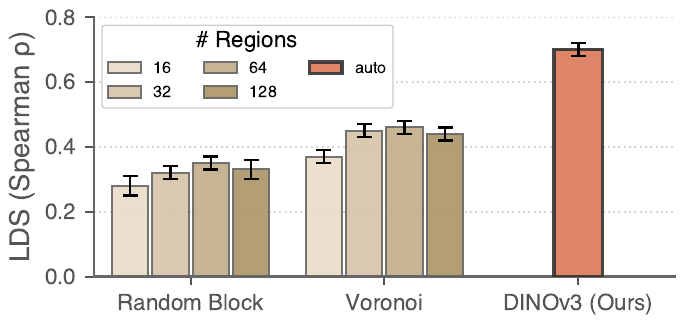
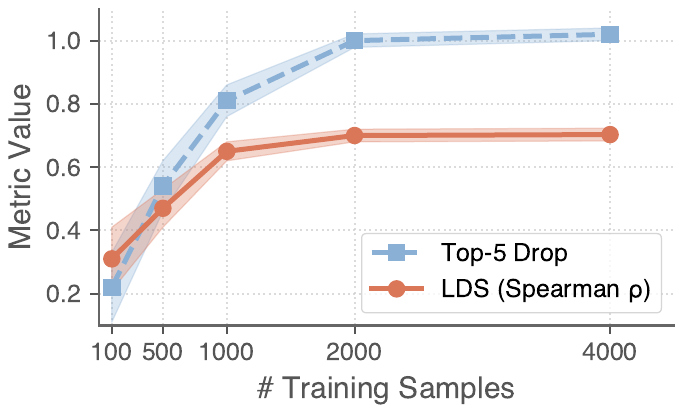
vSTREAM addresses this trade-off through amortized attribution: a linear estimator trained to predict region ablation effects from attention features, so faithful grounding evidence can be produced during generation rather than reconstructed afterward.
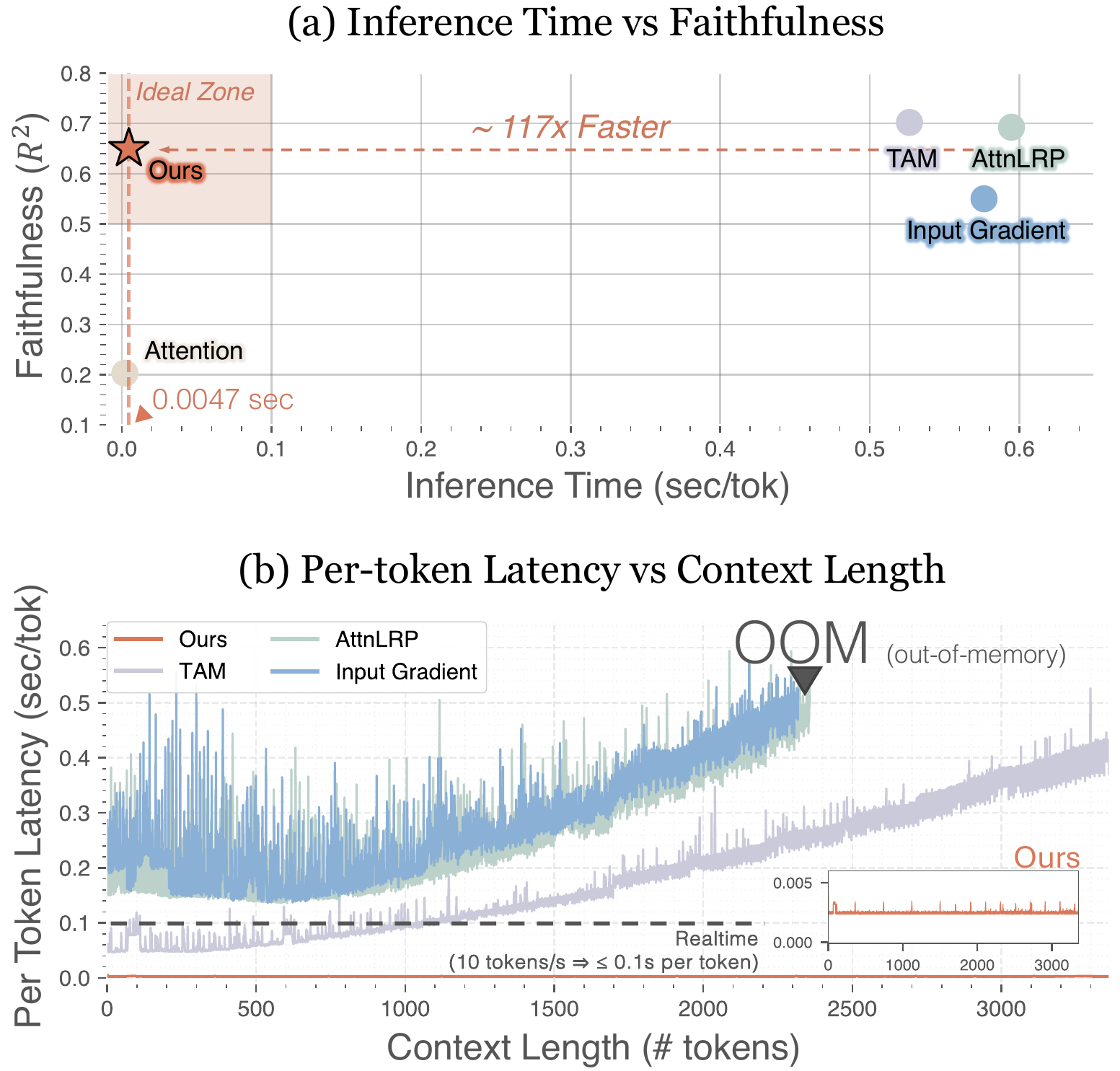
Figure 1. Existing attribution methods face competing demands of faithfulness and efficiency. vSTREAM sits in the top-right region, remaining faithful while running in real time.